Observability as a Delivery Enabler

Observability as a Delivery Enabler
The Growing Importance of Observability
Observability is becoming increasingly important in the modern enterprise as IT landscapes become more complex and distributed. When communicating the value of observability, technologists usually focus on the how it can help lower Mean Time to Detection (MTTD) and Mean Time to Resolution (MTTR)[i]. This may be a great way to communicate the value of observability to IT or Operations teams, but it is not always the case that the people troubleshooting performance issues report through IT leadership. Instead of IT, the technical staff in many organizations may report to Marketing, Product Development, Program Management, or some other business unit.
Don’t get me wrong, the folks in these other areas of the business certainly understand that there are benefits to lowering MTTD and MTTR, but if they aren’t tracking those metrics as KPIs on their teams, then appealing to them may not be the most effective way to communicate the value of observability.
When talking with these businesses, we prefer to frame the business value of observability as a delivery enabler. Rather than point to metrics that teams may or may not be tracking, we frame the issue in terms of the challenges that developers and product owners in all business units experience regardless of which KPIs they use. These challenges are: 1.) keeping delivery priorities on track when performance issues arise, and 2.) protecting the investment businesses make in their people and culture.
Minimizing the impact on your delivery priorities
In 2022 I was helping one of the largest non-profit healthcare providers in the United States implement New Relic as their observability platform. While we were still in the process of rolling the platform out, one of the teams reached out to me and asked if I could join a call. There were over 25 people on the call (developers, tech leads, architects, product owners, etc.) and as I joined, the tech lead told me they were struggling to figure out why their application was failing. The team had been completely blocked for 2 days, and the issue was impacting the deployment schedule of another team as well.
This is a common challenge in organizations with large distributed systems and multiple delivery teams. Fortunately, we had already instrumented most of the system. We used New Relic and within 10 minutes the tech lead, product owner, and I had the problem identified.
Let that sink in for a minute. Observability enabled 3 people to accomplish something in 10 minutes that had eluded dozens of people for days. If we had started there, no one would have been blocked and deployments wouldn’t have been in jeopardy.
As DevOps gains wide adoption, delivery teams are impacted by performance degradation in their systems since they are responsible for both the development and operation of their applications. Deadlines for delivering new or improved features may be adversely affected if the team has to dedicate too many hours to troubleshooting issues affecting their applications, and since performance issues tend to cascade through a distributed system, the root cause of the issue plaguing the team may not even be part of their application. This was the case in the anecdote above, which is why they had so much trouble identifying the issue.
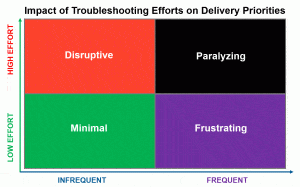
When considering the impact of troubleshooting efforts, we notice that issues that require a high level of effort to resolve are at best disruptive to delivery priorities and at worst paralyzing, depending on their frequency. Our goal with observability is to lower the effort required to identify and resolve performance issues, and to bring troubleshooting efforts down below the bar, so that the team’s ability to deliver value for the business isn’t disrupted.
Delivery teams don’t want to be blocked by performance issues. This is true regardless of whether they are part of IT, Marketing, or Product Development. With the ease of access and clear visibility[ii] that a well-designed observability platform provides, we can lower the effort required to identify performance issues and improve the team’s ability to resolve the issue without negatively impacting current priorities.
We also enable the team to lower the frequency of the issues, and when performance issues are infrequent and don’t require a high level of effort to identify, the impact to delivery priorities is minimal and team schedules don’t get derailed.
Protecting your investment in your people
Another important benefit to minimizing the impact of performance issues on delivery priorities is an improved developer experience and team environment. Businesses invest heavily in their people and team cultures, and developer experience is a critical aspect of the health and culture of DevOps teams.
I’m not going out on a limb when I say developers enjoy writing code and developing applications, and when developers can stay focused on their tasks there’s a certain momentum that builds which contributes to a sense of satisfaction in their work. Interruptions are inevitable, but when things like troubleshooting become frequent and difficult due to the inherent complexity of the system, it can negatively impact the morale of the team, especially when they know the root cause may not even be part of their application.
Eventually, this can lead to team leadership seeing higher rates of burnout and turnover, which undercut the investment the business has made in its people.
Of course, there are many contributing factors to team culture and burnout, but the level of effort required to perform routine tasks like troubleshooting can impact a team’s morale in a significant way.
A well-designed observability implementation addresses this directly. When the impact of performance issues on delivery is minimized, developers can maintain their momentum without being drawn into long, difficult troubleshooting sessions. The result is an improved team environment where developers are less likely to experience burnout.
If you’ve been hearing that observability can help you lower MTTD and MTTR but your teams don’t actively track those metrics, your business can still benefit from observability in a powerful way as a delivery enabler. By lowering the effort required to identify the source of performance issues, observability minimizes the impact on delivery priorities and timelines. It also protects your investment in your people by helping delivery teams spend more time doing what they love, which contributes positively to the health and culture of your teams.
Sources:
[i] Mean Time to Detection (MTTD) and Mean Time to Resolution (MTTR) are metrics typically used by operations teams in reliability engineering. They refer to the average time between when an incident occurs and when the responsible parties acknowledge the incident (MTTD) and resolve it (MTTR).
[ii] In an InfoQ podcast, Ben Sigelman, CEO of Lightstep defined clear visibility as the completeness of data related to performance, and ease of access as the ability to correlate and view the data and context in order to confirm or rebut hypotheses about possible root causes.